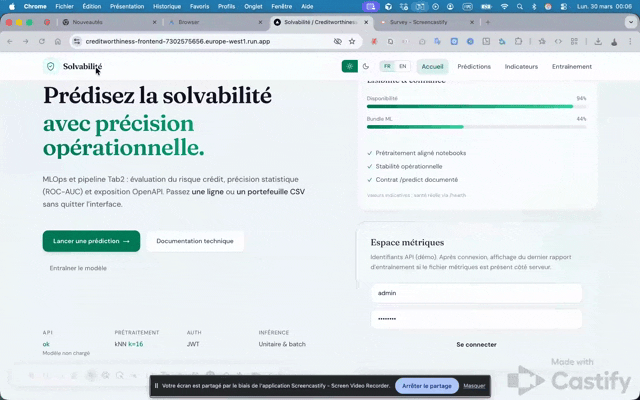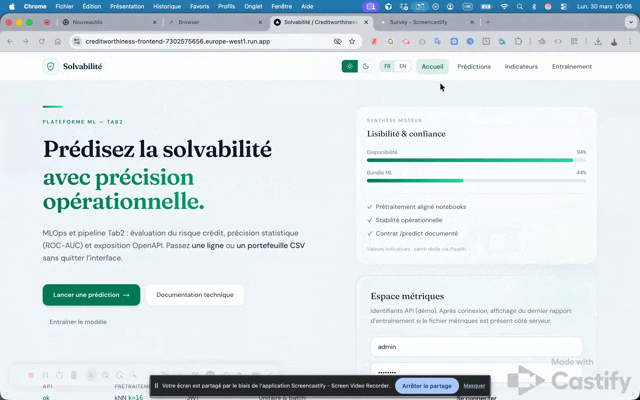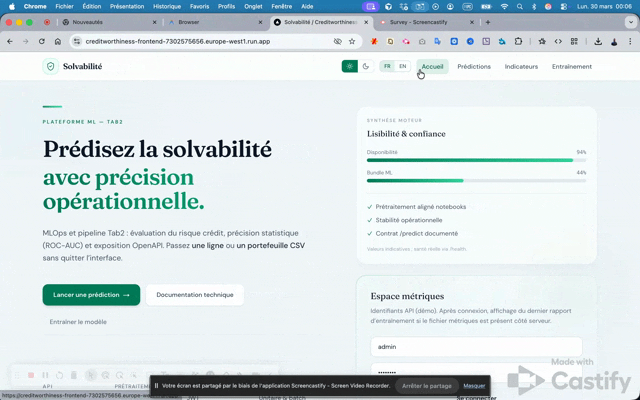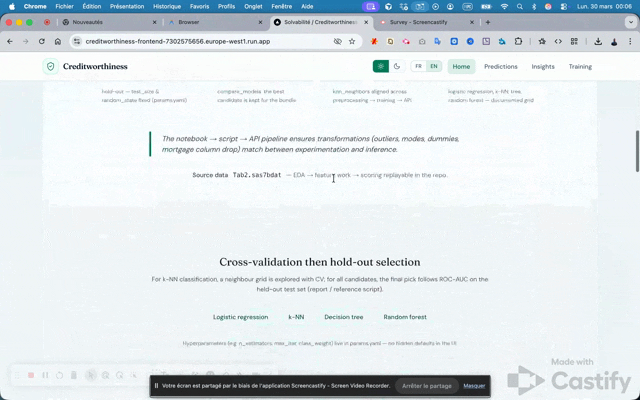
MLOps et pipeline Project Data : évaluation du risque crédit, précision statistique (ROC-AUC) et exposition OpenAPI. Passez une ligne ou un portefeuille CSV sans quitter l’interface.
Identifiants API (démo). Après connexion, affichage du dernier rapport d’entraînement si le fichier métriques est présent côté serveur.
Démonstration
La plateforme en mouvement
GIF enregistrés dans le dépôt (dossier assets/, servis sous /demo). L’ordre et les fichiers peuvent être pilotés par l’API GET /demo/carousel-manifest.
Les choix d’évaluation et de prétraitement reflètent le livrable académique et le fichier params.yaml — mêmes séparations train/test, métrique de sélection et imputation kNN que dans les notebooks.
Le pipeline notebook → script → API garantit que les transformations (outliers, modes, dummies, retrait Montant_hypotheque) sont identiques entre expérimentation et inférence.
Donnée sourceProject Data — fichier SAS Tab2.sas7bdat (référence académique) — chaîne EDA → features → scoring rejouable dans le dépôt.
Sélection par validation croisée puis hold-out
Pour le k-NN classifieur, une grille de voisins est explorée en CV ; pour tous les candidats, la décision finale suit la ROC-AUC sur la partition de test (rapport / Scrypt).
Régression logistiquek-NNArbre de décisionForêt aléatoire
Hyperparamètres (ex. n_estimators, max_iter, class_weight) définis dans params.yaml — pas de « boîte noire » côté interface.
Lexique ML
Que signifient les types de modèles ?
La plateforme compare plusieurs algorithmes classiques de classification binaire (solvable / défaut). Voici, en termes simples, ce que chacun fait — sans équations.
Régression logistique
Modèle qui combine linéairement les variables (après mise à l’échelle) pour estimer une probabilité entre 0 et 1. Très utilisé en scoring crédit : rapide, stable, facile à expliquer. Ici, les classes déséquilibrées peuvent être prises en compte via une pondération (class_weight) dans params.yaml.
k plus proches voisins (k-NN)
Pour un nouveau dossier, le modèle regarde les k profils les plus ressemblants dans les données d’apprentissage et vote avec leur étiquette (défaut ou non). Pas d’hypothèse de relation linéaire. Le nombre k est choisi par validation croisée sur une grille ; les variables doivent être comparables (d’où le prétraitement et l’échelle).
Arbre de décision
Enchaînement de règles du type « si la variable X est au-dessus d’un seuil, aller à gauche, sinon à droite » jusqu’à une feuille qui donne la classe. Très lisible pour un contrôle métier. Risque de sur-apprentissage si l’arbre est trop profond — limité par des paramètres comme min_samples_split.
Forêt aléatoire
Construit de nombreux arbres sur des sous-échantillons et des sous-ensembles de variables, puis agrège leurs votes (ou probabilités). Souvent très performant et robuste au bruit ; moins trivial à expliquer qu’un seul arbre, mais reste une référence en pratique pour le tabulaire.
SVM (machine à vecteurs de support) : optionnel dans params.yaml (souvent désactivé). Il cherche une frontière qui sépare au mieux les classes dans un espace de features ; peut être plus coûteux sur de très gros volumes.
Le pipeline retient automatiquement le meilleur candidat selon la métrique principale (ROC-AUC par défaut), puis l’accuracy en secours — voir params.yaml et la page Indicateurs pour le modèle effectivement chargé.
Architecture de performance
Un socle ML et API pensé pour la reproductibilité et l’industrialisation progressive.
Performance ML
Comparaison de modèles (régression logistique, k-NN, arbres, forêt), sélection ROC-AUC et bundle sérialisé unique pour notebook et API.
Propulsé par FastAPI
Latence maîtrisée, schémas pydantic, JWT sur /predict et /train, documentation interactive Swagger et schéma OpenAPI JSON.
MLOps & traçabilité
Artefacts versionnés, métriques /metrics après entraînement, contrat machine GET /ml/preprocess-contract pour vos intégrations.
Une stack résiliente pour la finance
Technologies du dépôt — du notebook à l’UI et au conteneur.
Python
FastAPI
Scikit-learn
N
Next.js
Docker
Cloud-ready
Architecture du pipeline
Aperçu des étapes reproduites côté serveur, comme dans les notebooks et le script de référence.
Le préprocesseur fitted (modes, outliers, KNNImputer, dummies) et le classifieur retenu sont sérialisés ensemble : même comportement en notebook, API unitaire et API batch.
✓ Cible binaire alignée Incident_r
✓ Métrique principale ROC-AUC (params.yaml)
✓ Réponse : classe + P(défaut)
Données brutes
SAS / CSV avec les noms colonnes attendus par l’API.
Qualitatives
Mode sur Motif_pret & Profession, puis one-hot drop-first.
Quantitatives & export
Outliers → NaN, imputation kNN, puis inférence. Lot : tableau + téléchargement CSV des scores.
Parcours en trois temps
1
Ingestion
Variables Project Data ; âge crédit en mois à la saisie.
Réponses courtes ; détail technique dans OpenAPI et les notebooks.
Pourquoi l’âge du crédit est-il en mois ?▼
Le jeu de données Project Data provient du SAS historique : l’API accepte les mêmes unités qu’à la source. Le préprocesseur convertit en années avant imputation et modèle.
Combien de lignes puis-je envoyer en lot ?▼
La limite est fixée côté serveur (variable PREDICT_BATCH_MAX_ROWS, exposée dans GET /ml/preprocess-contract). Le front affiche la valeur au moment du chargement de la page Prédictions.
Que contient le CSV exporté après un lot ?▼
Toutes les colonnes d’entrée plus la classe prédite, le verdict (solvable / non solvable), la probabilité de défaut et le nom du modèle utilisé.
Le modèle est-il « prêt production » ?▼
Cette plateforme illustre un pipeline académique reproductible. Un usage réglementé nécessite validation métier, monitoring et gouvernance des données.
Contact & réalisateur
Pour échanger sur le produit, la data ou les intégrations bancaires — liens professionnels ci-dessous.